Prinzipielles Vorgehen beim Profiling
Das Profiling erfolgt über das JVM Tool Interface (JVMTI). Ab Java 5 ersetzt diese Schnittstelle das JVMPI (JVM Profiling Interface) und JVMDI (JVM Debugging Interface). An diese Schnittstelle kann sich ein Profiling-Agent anmelden, der sich an Ereignisse der JVM bindet und die dabei anfallenden Daten sammelt. Diese Daten werden dann von einem geeigneten Tool aufbereitet und visualisert. Jedes Profiling besitzt damit die Bestandteile
- Starten einer JVM mit aktivierten Profiling Optionen
- Agent für das Abgreifen und Aufbereiten dieser Informationen
- Benutzerschnittstelle für die Präsentation und Analyse
Zeitverhalten oder Speicherbelastung
Beim Profiling lassen sich grob zwei Sachverhalte messen und untersuchen:
- Zeitverhalten: hier soll ermittelt werden, wie lange die JVM für die Abarbeitung von Methoden braucht, wie lange sie sich im Kontext einer Methode aufhält. Das kann man exakt aber aufwändig tun, indem die Ablaufzeiten gemessen werden, oder man nimmt Stichprobem (samples) und extrapoliert die Zeiten. Bei Performanzproblemen versucht man dann die "oft besuchten Langläufer" schneller zu machen.
- Speicherbelastung: hier ermittelt man die Belegung des Heaps mit Objektinstanzen. Insbesondere wenn sich der Heap mit der Zeit füllt und am Ende eine OutOfMemory Ausnahme auslöst, muss herausgefunden werden, warum welche Instanzen von der GC nicht beseitigt werden können.
HPROF ist ein experimenteller Profiling Agent von Sun. Kleiner Footprint, erzeugt riesiege Dumpfiles, die mit einem Tool untersucht werden können. Geeignet für schnelle Ergebnisse auch im professionellen Bereich.
- JVMTI Binding: über die Startoptionen -Xrunhprof:<optionen>, -XX:+HeapDumpOnOutOfMemoryError oder -XX:+HeapDumpOnCtrlBreak oder mit Tools: JConsole ab Java 6 (Windows), JVMMon für die SAP JVM oder mit jmap ab Java 5 (Linux, Mac OS)
- Agent: keiner, Filedump
- Benutzerschnittstellen: jhat, im JDK integrierte Swing GUI zur Visualisierung der Dumpfiles jhat und Eclipse Memory Analyzer Tool
Ab dem JRE 1.6 bietet JMX eine komfortable Möglichkeit für das Erzeugen von Heapdumps zur Laufzeit der Anwendung. Mit der Startoption
-Dcom.sun.management.jmxremotelässt sich eine Anwendung remote administrieren. Dazu jconsole starten und mit dem Prozess der Anwendung verbinden. Anschließend unter MBeans com.sun.management.HotSpotDiagnostic anwählen und mit dumpHeap einen Heap-Dump erzeugen (vorher als Argument einen Namen für das Dumpfile angeben!).

Zum Auswerten eines Heapdumps bringt das Eclipse Memory Analyzer Tool den besten Kompromiss zwischen Geschwindigkeit und Komfort. Außerdem kann er die begehrten Heapdump-Differenzen darstellen.
Jedes Objekt nutzt Speicher der JVM für seine Referenzen auf andere Objekte (jede Referenz = 4 Byte, 8 Byte in einer 64 Bit Umgebung) und seine Primitiven (4 oder 8 Byte). Das ist die shallow heap size des Objekts. Viel interessanter ist die retained heap size, der (geschätzte) Speicher der frei wird, wenn das Objekt von der GC abgeräumt wird. Diese retained heap size ist die wesentlich interessantere Größe. Grundlage zur Ermittlung der retained heap size ist der dominator tree des Heapdumps. Dabei wird eine Hierarchie aufgebaut, für die folgendes gilt: eine Node-Subnode Beziehung besteht, wenn alle Referenzen zu Subnode über Node gehen. Der dominator tree zeigt also nicht die wahre Referenzbeziehung zwischen Objekten, aber er identifiziert "easy targets". Objekte mit einer großen retained heap size sind die besten Kandidaten für Optimierung.
Nun kann man durch geeignete Korrekturen im Code dafür sorgen, die retained heap size solcher Kandidaten zu verkleinern, oder man schafft es, diese Kandidaten schneller einer GC zuzuführen.
Selten wird man erreichen, dass in produktiven Umgebungen Server mit JMX Remote Services gestartet werden dürfen. Ab JRE 1.6 kann man aber die nötigen Profilinginformationen zur Laufzeit sammeln und über die Schnittstellen der Anwendung bereitstellen (zum Beispiel über ein Servlet). Interessiert man sich für das Zeitverhalten der Anwendung, nutzt man die Thread Info API des JDK, im Sun JDK ist das im Wesentlichen die ThreadInfo Klasse:
// einmal
ThreadMXBean mxbean = ManagementFactory.getThreadMXBean();
//
// die folgende Schleife für ein aussagekräftiges Sampling sehr oft wiederholen,
// zum Beispiel 100 Sekunden lang alle 10 Millisekunden
ThreadInfo[] threadInfoArray = mxbean.dumpAllThreads(true, true);
for (int i = 0, l = threadInfoArray.length; i < l; i++) {
ThreadInfo info = threadInfoArray[i];
StackTraceElement[] traceArray = info.getStackTrace();
..
}
Die Stacktraces können nun gezählt werden, was im Ergebnis einem Timesampling entspricht. Die Stacktrace-Informationen können außerdem in einer Hierarchie einsortiert und als HTML Seite von einem Servlet bereitgestellt werden, hier ein Beispiel:
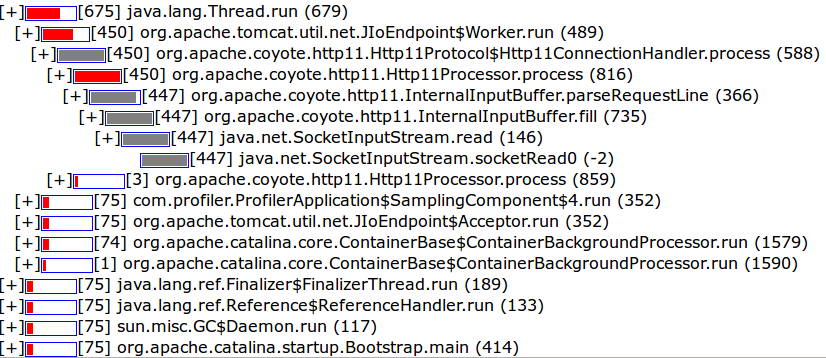
Da die produktive JVM nur für die kurze Dauer des Timesamplings belastet wird, ist ein solches Vorgehen in produktiven Umgebungen nach Rücksprache mit dem verantwortlichen Operating vielleicht akzeptabel und kann ungemein nützlich sein.
Über die JMX API kann auch ein Heapdump im produktiven System erzeugt werden:
// Vorbereiten der HotspotMBean
String HOTSPOT_BEAN_NAME = "com.sun.management:type=HotSpotDiagnostic";
MBeanServer server = ManagementFactory.getPlatformMBeanServer();
HotSpotDiagnosticMXBean hotspotMBean = ManagementFactory.newPlatformMXBeanProxy(server,
HOTSPOT_BEAN_NAME, HotSpotDiagnosticMXBean.class);
//
// schreiben des Heapdumps in ein File
hotspotMBean.dumpHeap(filenameString, true);
Hier muss allerdings mit Fingerspitzengefühl vorgegangen werden, denn ein solcher Dump kann viele Hundert Megabyte groß sein und wird das System für eine kurze Dauer stark belasten. In jedem Fall muss die Auswertung des Heapdumps außerhalb der Produktivumgebung erfolgen. Der erzeugte Heapdump muss also über Netzwerkfileschnittstellen aus der produktiven Umgebung in eine Entwicklungsumgebung transportiert werden, was abermals die Produktivumgebung stark belastet und niemals ohne Absprache mit dem zuständigen Operating passieren darf. Steht in der produktiven Umgebung ein Servletcontainer zur Verfügung, kann man die Übertragung des Heapdumps auch über einen Servlet-Filedownload (also über HTTP) bewerkstelligen.
TPTP - Test and Performance Tools Plattform
Die Test and Performance Tools Plattform (bis Java 1.4 - Trace and Profiling Tools Project) nutzt das Java Virtual Machine Tool Interface (JVMTI, früher JVMPI) und ist integriert in die Eclipse IDE (TPTP).
- JVMTI/JVMPI Binding: -XrunpiAgent:server=enabled Mit dieser Option wird das Profiling und das Sammeln von Daten von TPTP Client aus gesteuert (andere Optionen möglich)
- Die Hyades Data Collection Engine muss auf dem Server auf dem die untersuchte JVM läuft, gestartet werden.
- Benutzerschnittstelle: das TPTP Eclipse Plugin
Proprietär: Profiling mit der JRockit - JRCMD
Die aktuelle Version von JRockit beinhaltet eine Tool mit dem man grundlegende JVM Eigenschaften untersuchen kann. Es eignet sich hervorragend für eine schnelle Analyse bei Laufzeitproblemen mit der JRockit JVM und man kann es intuitiv erlernen. 'jrcmd' ohne Parameter gibt alle laufenden JRockit JVM Prozesse und den Namen der Main-Klasse.
> jrcmd > 1825 weblogic.Server > 2334 com.util.LauncherAuf einen dieser Prozesse bezieht man sich nun. Aber zunächst kann man sich mit der help-Option alle Kommandos anschauen. Noch mehr Informationen gibt es mit jrcmd
memprof: Memory leak detection
sampleRate - number of seconds between samples (default: 10s)
trendSize - number of positive samples to consider (default: 5)
forceThreshold - size in bytes to force full stack stats (default: 250k)
verboseResultStats - print all known stats, not just leaking (default: false)
runsystemgc: java.lang.System.gc()
runfinalization: java.lang.System.runFinalization()
heap_diagnostics: heap diagnostic
print_class_summary: alle geladenen Klassen
print_object_summary: Objekte auf dem Heap
name1, name2, name3 - Klassennamen, die gezeigt werden sollen (mit / statt .)
increaseonly - (bool) zeige nur Klassen die zunehmen
largestarrays - zeige die 10 größten Arrays vom Typ name1
activatetrendanalysis - Trendanalysis, relativer Zuwachs nach jeder GC.
deactivatetrendanalysis - Trendanalyse aus
print_properties -> int the Java and VM properties.
Echte Analysen brauchen auch hier Werkzeuge, die die enorme Datenflut beim Profiling visuell aufbereiten. Hier lassen sich mit
jrcmd 1234 jrarecording time=600 filename=prof.xml.zipProfiling-Dumpfiles erzeugen und anschließend mittels eines GUI (der JRA) untersuchen. Ein Profil kann übrigens auch über Startoptionen des Servers oder über die Managementkonsole angelegt werden. Leider müssen für diese Profiling-Funktionen extra Lizenzen gekauft werden.
Manipulation von java.lang.Object
Kommt ein Einsatz professioneller Profiling-Werkzeuge nicht in Frage, kann man vielleicht auf der Sprachebene improvisieren. So ließen sich alle angelegten Objektinstanzen zählen, indem man im Konstruktor von java.lang.Object (den ja alle Konstruktoren durchlaufen) einen Zähler hochzählt und in finalize entsprechend runterzählt.}
Dazu ist zunächst die Klasse java.lang.Object entsprechend zu manipulieren. Aus den Java-Quellen legt man sich eine Kopie von java.lang.Object in den Workspace und compiliert die Klasse ganz normal mit dem JDK:
public class Object {
:
public Object() {
System.out.println(this.getClass().getName());
}
:
}
Startet man nun ein Testprogramm passiert - zunächst garnichts. Ja, richtig. Hier ist zwar eine manipulierte Version der Klasse java.lang.Object erstellt worden, allerdings nimmt die Laufzeit standardmäßig die Klassen des JRE, da diese Bestandteil des Bootclasspath sind. Es muss deshalb beim Starten der Anwendung der Bootclasspath manipuliert werden:
-Xbootclasspath/p: <Pfad zur manipulierten java.lang.Object.class>Das Programm wird erneut gestartet und nun passiert etwas:
Error occurred during initialization of VM java.lang.StackOverflowErrorDer Grund dafür findet sich in der rekursiven Verwendung eines Konstruktors innerhalb des Konstruktors von java.lang.Object. Die Zeile System.out.println(this.getClass().getName()) erzeugt Objektinstanzen, die wiederum durch den Konstruktor von java.lang.Object laufen müssen und so fort. Eine Möglichkeit zur Behebung des Problems besteht vielleicht darin, keine Konstruktoren innerhalb des manipulierten Konstruktors von java.lang.Object zu rufen. Da aus genannten Gründen auch im statischen und nichtstatischen Initialisierungsbereich von java.lang.Object keine Objektinstanzen angelegt werden dürfen, ist dieses Vorgehen nutzlos. Es muss eine andere Lösung gefunden werden.
Innerhalb eines synchronisierten Bereichs im Konstruktor von java.lang.Object wird ein Flag gesetzt, das dafür sorgt, dass während der Abarbeitung nun keine Objektinstanzen erzeugt werden. Beim Verlassen des Konstruktors wird das Flag wieder zurückgesetzt.
public class Object {
:
private static boolean inConstructor = true;
//
public Object() {
synchronized(Object.class) {
if (!inConstructor) {
inConstructor = true;
System.out.println(this.getClass().getName());
inConstructor = false;
}
}
}
//
public static void trace() {
synchronized(Object.class) {
inConstructor = false;
}
}
:
}
//
:
public static void main(String[] args) {
//
Object.trace();
//
JFrame frame = new JFrame();
frame.setDefaultCloseOperation(JFrame.DISPOSE_ON_CLOSE);
frame.show();
//
}
:
Bei diesem Vorgehen werden die Objektinstanzen innerhalb des Konstruktors von java.lang.Object und vor dem Aufruf von Object.trace() nicht bei der Abarbeitung erfasst. Das ist für die Zwecke des Profilings normalerweise auch nicht notwendig.
Unbedingt hinzugefügt werden muss, dass derart manipulierte Laufzeiten nicht ausgeliefert werden dürfen. Insgesamt ist diese Vorgehen also eher was für den Hobbybereich.
Java and android performance analysis, Eclipse Memory Analyzer
J2SE Monitoring